5 min read
The Complete Fine-Tuning Process for LLM Models
A comprehensive guide to fine-tuning Large Language Models (LLMs). Learn when to fine-tune, how to select the right model, prepare your dataset, execute training, and deploy with confidence to optimize LLM performance for your use cases.

Complete Guide to Fine-Tuning Large Language Models
Introduction
Large Language Models (LLMs) have revolutionized the way we build AI applications, but their out-of-the-box performance isn't always perfect for specific use cases. This comprehensive guide will walk you through the process of fine-tuning LLMs and implementing robust evaluation metrics to ensure your model performs optimally for your specific needs.
Understanding Fine-tuning: What, Why, and When?
Fine-tuning is the process of taking a pre-trained language model and further training it on a specific dataset to adapt it for particular tasks or domains. Think of it like taking a generally educated person and giving them specialized training in a specific field.
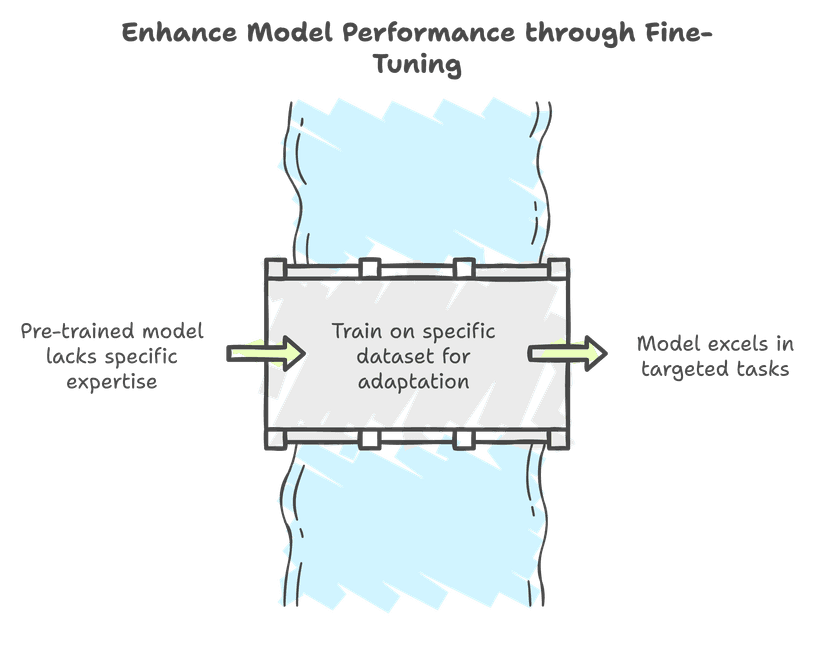
When Should You Fine-tune?
- When you need domain-specific knowledge
- When you want to improve performance on specific tasks
- When you need consistent output formats
- When you want to reduce hallucinations for your use case
When Should You Not Fine-tune?
- When prompt engineering can solve your problem
- When you don't have enough high-quality training data
- When you need general knowledge capabilities
- When computational resources are limited
Step 1: Choosing Your Pre-trained Model
Evaluate Model Suitability
- Assess task alignment: Does the base model specialize in similar tasks (e.g., classification, generative, sequence-to-sequence)?
- Consider performance benchmarks on related datasets
Technical Considerations
- Model size, hardware, and compute budget (e.g., GPUs, TPUs)
- Inference latency requirements for production deployment
Legal and Ethical Aspects
- Licensing constraints (e.g., OpenAI, Meta's LLaMA, open-source models)
- Compliance with organizational and regional policies
Popular Base Models
- BERT/RoBERTa: Excels in classification, token tagging, and contextual embedding
- GPT Family: Best for generative tasks with flexible output structures
- T5: Tailored for sequence-to-sequence tasks (e.g., translation, summarization)
- Domain-Specific Models: BioBERT, LegalBERT, and others for niche applications

Step 2: Preparing Your Dataset
Data Collection
- Gather domain-specific, high-quality datasets to match the task requirements
- Ensure diversity and balance to avoid introducing bias
Data Preprocessing
- Clean raw data by handling missing values, duplicates, and noise
- Normalize text (e.g., lowercasing, punctuation handling) while retaining domain-specific nuances
Data Annotation
- Label data accurately using domain experts
- Follow annotation guidelines to maintain consistency and relevance
Dataset Splitting
- Split into training, validation, and test sets (e.g., 70/20/10 split) with stratified sampling for class balance
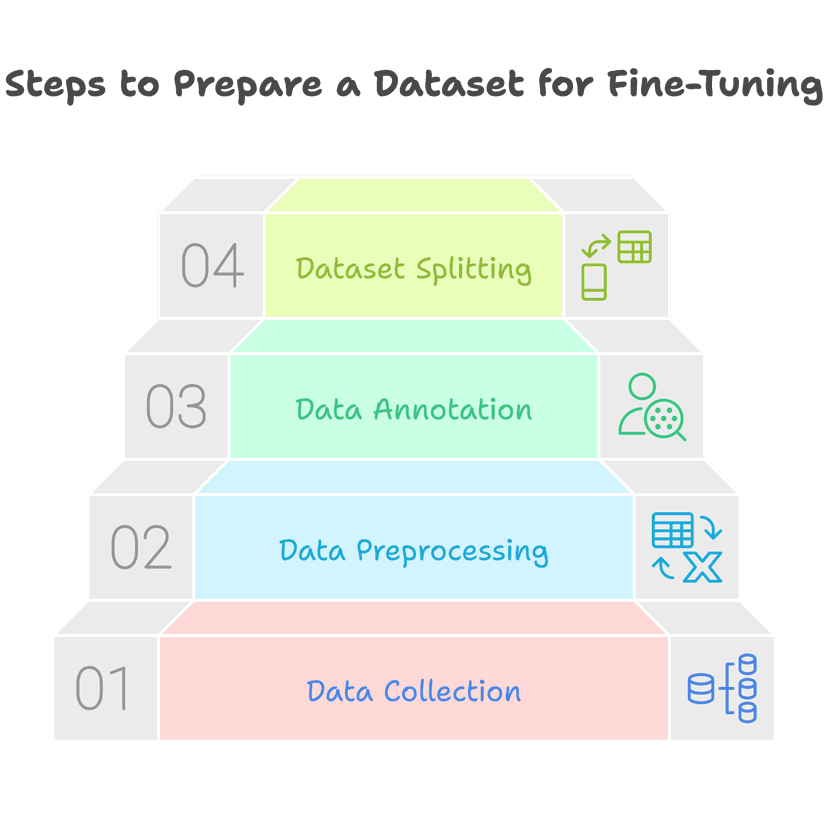
steps-to-prepare-a-dataset-for-fine-tuning.png
Tokenizer Selection
- Use the tokenizer provided with the pre-trained model to maintain compatibility
- Customize for specific needs (e.g., domain-specific vocabulary, byte-pair encoding)
Vocabulary Extension
- Add domain-specific tokens to the tokenizer vocabulary for better representation
Optimization
- Analyze sequence lengths to set optimal padding and truncation strategies
- Reduce memory overhead by batching based on sequence length
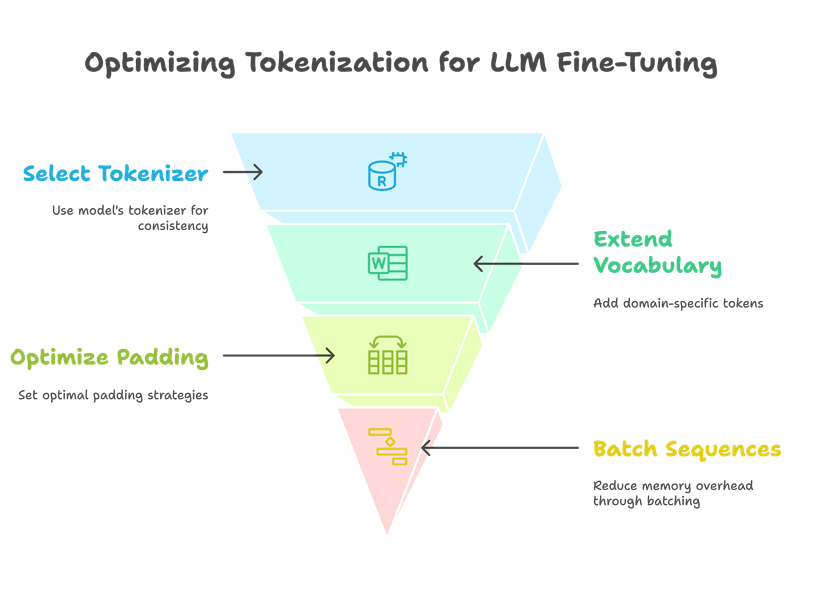
Step 4: Model Initialization
Load Pre-trained Weights
- Initialize with base model weights to leverage transfer learning
- Freeze or partially freeze layers if the base model is over-specialized or limited in data
Configure Model
- Adjust hyperparameters (e.g., learning rate, dropout rates) for fine-tuning
- Define task-specific heads (e.g., classification head for BERT, language modeling head for GPT)

Step 5: Training Loop Setup
Optimizer and Learning Rate Scheduler
- Use optimizers like AdamW for effective gradient updates
- Employ learning rate warm-up and decay strategies to stabilize training
Loss Function
- Define task-specific loss (e.g., cross-entropy for classification, BLEU for translation)
Batch Management
- Implement dynamic batching for computational efficiency with variable-length inputs
Evaluation Metrics
- Monitor task-relevant metrics (e.g., accuracy, F1, perplexity) for robust evaluation

Step 6: Fine-tuning Execution
Training Execution
- Use distributed training for large models (e.g., multi-GPU or TPU setups)
- Implement gradient accumulation to handle memory constraints on smaller GPUs
Regularization Techniques
- Apply dropout, weight decay, and gradient clipping to avoid overfitting
Validation Loop
- Continuously evaluate on the validation set to monitor convergence and avoid overfitting
Checkpointing
- Save checkpoints regularly to recover from interruptions and track performance


Step 7: Post-Fine-Tuning Optimization
Model Quantization:
- Reduce model size and latency through techniques like INT8 quantization
Knowledge Distillation:
- Use a smaller model (student) to approximate the fine-tuned model (teacher) for deployment efficiency
Testing
- Evaluate performance on unseen test data to validate generalizability
- Conduct domain-specific robustness tests (e.g., adversarial inputs)

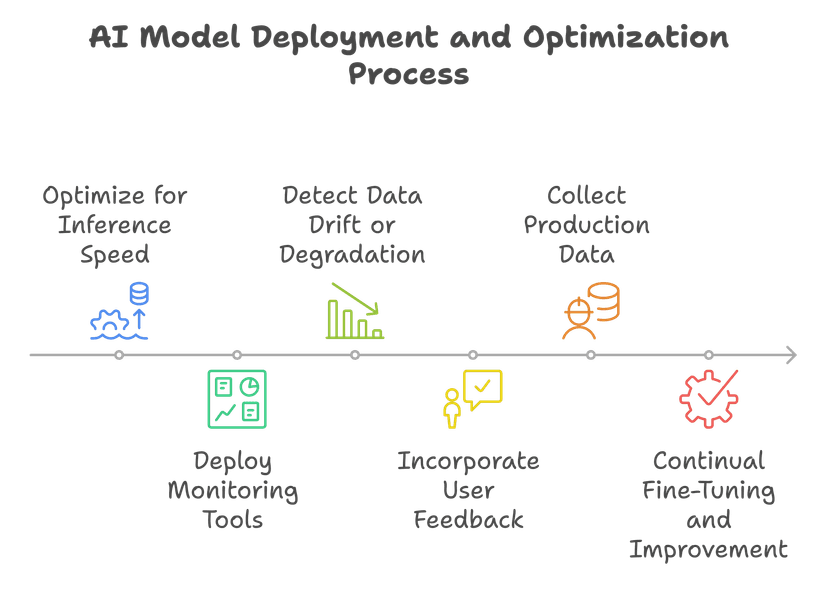
Step 8: Deployment Preparation
Scalability:
- Optimize for inference speed and scalability using model serving platforms (e.g., TensorFlow Serving, TorchServe)
Monitoring:
- Deploy real-time monitoring tools to detect data drift or performance degradation in production
Feedback Loop:
- Incorporate user feedback and collect production data for continual fine-tuning and improvement
Conclusion
Effective LLM evaluation requires a combination of:
- Well-designed metrics
- Comprehensive test suites
- Continuous monitoring
- Regular refinement
Remember that evaluation is not a one-time process but a continuous cycle of measurement, analysis, and improvement. By following these guidelines and implementing robust evaluation frameworks, you can ensure your fine-tuned LLMs perform optimally for your specific use cases.